Recent searches
Search options

Administered by:



#LLMs



"Now consider the chatbot therapist: what are its privacy safeguards? Well, the companies may make some promises about what they will and won't do with the transcripts of your AI sessions, but they are lying. Of course they're lying! AI companies lie about what their technology can do (of course). They lie about what their technologies will do. They lie about money. But most of all, they lie about data.
There is no subject on which AI companies have been more consistently, flagrantly, grotesquely dishonest than training data. When it comes to getting more data, AI companies will lie, cheat and steal in ways that would seem hacky if you wrote them into fiction, like they were pulp-novel dope fiends:
(...)
But it's not just people struggling with their mental health who shouldn't be sharing sensitive data with chatbots – it's everyone. All those business applications that AI companies are pushing, the kind where you entrust an AI with your firm's most commercially sensitive data? Are you crazy? These companies will not only leak that data, they'll sell it to your competition. Hell, Microsoft already does this with Office365 analytics:
(...)
These companies lie all the time about everything, but the thing they lie most about is how they handle sensitive data. It's wild that anyone has to be reminded of this. Letting AI companies handle your sensitive data is like turning arsonists loose in your library with a can of gasoline, a book of matches, and a pinky-promise that this time, they won't set anything on fire."
https://pluralistic.net/2025/04/01/doctor-robo-blabbermouth/#fool-me-once-etc-etc
In other words, Generative AI and LLMs lack a sound epistemology and that's very problematic...:
"Bullshit and generative AI are not the same. They are similar, however, in the sense that both mix true, false, and ambiguous statements in ways that make it difficult or impossible to distinguish which is which. ChatGPT has been designed to sound convincing, whether right or wrong. As such, current AI is more about rhetoric and persuasiveness than about truth. Current AI is therefore closer to bullshit than it is to truth. This is a problem because it means that AI will produce faulty and ignorant results, even if unintentionally.
(...)
Judging by the available evidence, current AI – which is generative AI based on large language models – entails artificial ignorance more than artificial intelligence. That needs to change for AI to become a trusted and effective tool in science, technology, policy, and management. AI needs criteria for what truth is and what gets to count as truth. It is not enough to sound right, like current AI does. You need to be right. And to be right, you need to know the truth about things, like AI does not. This is a core problem with today's AI: it is surprisingly bad at distinguishing between truth and untruth – exactly like bullshit – producing artificial ignorance as much as artificial intelligence with little ability to discriminate between the two.
(...)
Nevertheless, the perhaps most fundamental question we can ask of AI is that if it succeeds in getting better than humans, as already happens in some areas, like playing AlphaZero, would that represent the advancement of knowledge, even when humans do not understand how the AI works, which is typical? Or would it represent knowledge receding from humans? If the latter, is that desirable and can we afford it?"

Anthropic flips the script on AI in education: Claude’s Learning Mode makes students do the thinking
https://zurl.co/LrB4H
#ai #genai #llms #aiforedu


 Classifying Genre in Historical Medical Periodicals
Classifying Genre in Historical Medical Periodicals
Next in line: Vera Danilova presents her work on genre classification in digitized periodicals from European patient organizations (1951–1990) using #LLMs as part of the #ActDisease project.
 XLM-RoBERTa (UDM) led Q&A tasks with 32% more correct answers than mBERT/hmBERT. hmBERT (UDM) topped Administrative classification (+16%) CORE-based models excelled in legal genre prediction.
XLM-RoBERTa (UDM) led Q&A tasks with 32% more correct answers than mBERT/hmBERT. hmBERT (UDM) topped Administrative classification (+16%) CORE-based models excelled in legal genre prediction.


#LLMs Pass the #TuringTest: Interrogators mistook GPT-4.5 for a human 73% of the time—far more than they did the actual human participant
 https://arxiv.org/abs/2503.23674
https://arxiv.org/abs/2503.23674

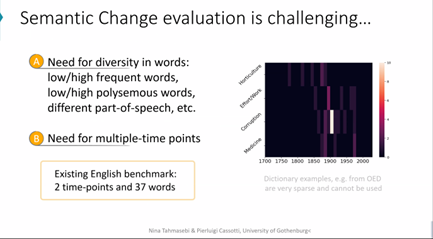
Large-Scale Text Analysis & Cultural Change
In their talk at the workshop “Large Language Models for the HPSS” @tuberlin Pierluigi Cassotti and Nina Tahmasebi presented a multi-method approach to studying cultural and societal change through large-scale text analysis.
By combining close reading with computational techniques, including but not limited to #LLMs , they demonstrate how diverse tools can be integrated to uncover shifts in language. #DigitalHumanities

The insatiable hunger to feed #LLMs and #AI is parasitically draining the commons and public internet. Bandwidth costs are spiking as crawlers take data for training and information. For Wikipedia, the lack of attribution means no visitors, no donors, just cost. The #ethics of AI are failing here.
I saw Tim Karr on bluesky suggest that AIs should pay fees or a tax (should that be tariffs?) into a fund that supports public content. Services like Cloudflare and Fastly that defend against bots are evolving for crawlers. In #identity, the implications for #AgenticAI, #AI, and #NHI are vast.
https://diff.wikimedia.org/2025/04/01/how-crawlers-impact-the-operations-of-the-wikimedia-projects/


Proof or bluff? Evaluating LLMs on 2025 USA math olympiad. ~ Ivo Petrov et als. https://arxiv.org/abs/2503.21934 #LLMs #Math

Readings shared April 1, 2025. https://jaalonso.github.io/vestigium/posts/2025/04/01-readings_shared_04-01-25 #AI #Haskell #ITP #IsabelleHOL #LLMs #LeanProver #Logic #LogicProgramming #Math #Prolog #SMT #Z3



"Prompt Engineering" for AI is this today's version of "Don't hold it that way" for the iPhone 4.
Users are misassigned blame for fundamental flaws in the technology, and are instructed to adopt behavioural workarounds. These improvised habits lack the causal power to fix underlying problems in the tech, but they serve to reinforce the notion that this new tech is superior to the tech it's trying to replace or "disrupt". Furthermore, users are taught, "Just keep trying and you'll get it right," without questioning whether the new tech is the problem, or to ask if the new tech has the potential to ever deliver on its promises.
A crucial difference between early smartphones and wishing that LLMs are a route to "Thinking Machines" is: later models of phones successfully matured the engineering of antennas and improved mobile reception, but LLMs are a dead-end that can never lead to real Artificial Intelligence.
This can be summarised by the AM/FM Principal: Actual Machines in contrast to Fucking Magic.




Bill Gates: "A.I. chatbots will teach kids to read within 18 months." (April 2023)
HEADLINE: 'No Longer Think You Should Learn To Code,' Says CEO of AI Coding Startup
CORRECTED: CEO Of Company Whose Flimsy Business Model Is Only Hypothetically Viable If You Cant Code For Yourself; Says You Should Stop Learning To Code.
"In a new joint study, researchers with OpenAI and the MIT Media Lab found that this small subset of ChatGPT users engaged in more "problematic use," defined in the paper as "indicators of addiction... including preoccupation, withdrawal symptoms, loss of control, and mood modification."
To get there, the MIT and OpenAI team surveyed thousands of ChatGPT users to glean not only how they felt about the chatbot, but also to study what kinds of "affective cues," which was defined in a joint summary of the research as "aspects of interactions that indicate empathy, affection, or support," they used when chatting with it.
Though the vast majority of people surveyed didn't engage emotionally with ChatGPT, those who used the chatbot for longer periods of time seemed to start considering it to be a "friend." The survey participants who chatted with ChatGPT the longest tended to be lonelier and get more stressed out over subtle changes in the model's behavior, too."


DeepMind Tightens Control Over AI Research to Guard Google’s Competitive Advantage
#AI #DeepMind #GoogleAI #GeminiAI #AIresearch #AlphaGeometry #AlphaFold3 #AGI #AIsecrecy #RoboticsAI #TxGemma #AIethics #OpenScience #LLMs






 **Are chatbots reliable text annotators? Sometimes**
**Are chatbots reliable text annotators? Sometimes**
“_Given the unreliable performance of ChatGPT and the significant challenges it poses to Open Science, we advise caution when using ChatGPT for substantive text annotation tasks._”
Ross Deans Kristensen-McLachlan, Miceal Canavan, Marton Kárdos, Mia Jacobsen, Lene Aarøe, Are chatbots reliable text annotators? Sometimes, PNAS Nexus, Volume 4, Issue 4, April 2025, pgaf069, https://doi.org/10.1093/pnasnexus/pgaf069.
#OpenAccess #OA #Article #AI #ArtificialIntelligence #LargeLanguageModels #LLMS #Chatbots #Technology #Tech #Data #Annotation #Academia #Academics @ai
The Rise of Specialized LLMs for Enterprise
https://zurl.co/h1EXx
#ai #genai #llms enterpriseai

